How Node js Works Behind the Scenes ?
Read This on Github
⭐ Node js Works: Event Loop
Explain

The Node.js event loop is what helps Node.js do many things at once without getting stuck. Even though JavaScript can only do one thing at a time, the event loop can send tasks to the computer's main processing unit to work on in the background. When a task is finished, the event loop gets notified and adds the next task to a list of things to do. When the main task is done, the event loop checks that list and starts working on the next task. This way, Node.js can do lots of things at once without waiting for each one to finish before starting the next.
⭐ Let's Understand the Event Loop
Explain

Let’s quickly take a look at an example and see what’s happening when we’re running the following code in a browser:
const foo = () => console.log("First");
const bar = () => setTimeout(() => console.log("Second"), 500);
const baz = () => console.log("Third");
bar();
foo();
baz();
Output:
First
Third
Second
- The browser creates a call stack and task queue. The call stack executes the code and the task queue stores tasks to be executed later.
- bar() is invoked, which returns a setTimeout() function.
- The callback function passed to setTimeout() is added to the Web API, and setTimeout() and bar() are popped off the call stack.
- While waiting for the timer to run, foo() is invoked and logs "First" to the console. foo() then returns, baz() is invoked, and the callback is added to the task queue.
- baz() logs "Third" to the console. After baz() returns, the event loop checks that the call stack is empty, and then the callback function is added to the call stack.
- The callback function logs "Second" to the console, completing the execution.
This is simple example we already discussed in the previous chapter. But let’s see what’s happening behind the scenes.
-
When we run this code, the browser creates a call stack and a task queue. The call stack is where the code is executed, and the task queue is where the tasks are stored. The call stack is a LIFO (last in, first out) data structure, which means that the last function that gets pushed into the stack is the first to be pop out, when the function returns.
-
The task queue, on the other hand, is a FIFO (first in, first out) data structure, which means that the first task that gets pushed into the queue is the first to be pop out, when the call stack is empty.
-
The event loop is constantly checking the call stack and the task queue. If the call stack is empty, it will take the first task from the task queue and push it to the call stack, which effectively runs it. This process will continue until the call stack is not empty or the task queue is not empty. Let’s see what happens when we run the code above:
⭐ Clearing The Confusion
Explain
I know it’s a bit confusing, but let’s break it down and see what’s happening in each step.
- This is the architecture of the event loop.
- The call stack is where the code is executed
- Node API is where the asynchronous tasks are executed
- The callback queue is where the callback functions are stored
- The event loop is constantly checking the call stack and the callback queue. If the call stack is empty, it will take the first task from the callback queue and push it to the call stack, which effectively runs it. This process will continue until the call stack is not empty or the callback queue is not empty.
- Call Stack is a LIFO (last in, first out) data structure & Callback Queue is a FIFO (first in, first out) data structure.

- You can see a simple code example below but you might be wondering why
main()function is already in the call stack before we invoke it.
- The reason is that the browser automatically adds the global execution context to the call stack when the page loads. This is why we can access the global variables and functions without explicitly calling them.
- This is similar to the main() function in C++ or Java. The main() function is the entry point of the program, and it’s automatically added to the call stack when the program starts.

- Next step when it reaches
console.log("sum is" + y)it will be added to the call stack aftermain()function.
- Now you might be wondering if lot of functions are added to the call stack, call stack will be full and why main() function is not popped out of the call stack before
console.log("sum is" + y)is added to the call stack.- The reason is that the call stack is a LIFO (last in, first out) data structure, which means that the last function that gets pushed into the stack is the first to be pop out, when the function returns and the main() function is not popped out of the call stack until
console.log("sum is" + y)is executed because all the functions are written in the main() function.

- So output will be
sum is 3andmain()function will be popped out of the call stack.


⭐ Explain with Example
console.log('Starting index.js');
setTimeout(() => {
console.log('Delay 2 seconds..');
}, 2000);
setTimeout(() => {
console.log('Delay 0 seconds..');
}, 0);
console.log('Finished index.js');You might think that the output will be:
- Starting index.js
- Delay 0 seconds..
- Finished index.js
- Delay 2 seconds..
Because first console.log() is executed and then setTimeout() is not executed immediately because it has a delay of 2 seconds and then setTimeout() has a delay of 0 seconds so it will be executed after console.log('Starting index.js') and then console.log('Finished index.js') will be executed and then setTimeout() with delay of 2 seconds will be executed.
But the output will be:
- Starting index.js
- Finished index.js
- Delay 0 seconds..
- Delay 2 seconds..
But why???
-
First
console.log('Starting index.js')is executed -
Now it reaches
setTimeout(() => { console.log('Delay 2 seconds..'); }, 2000);

- Now you might be wondering why
setTimeout()is present in the Node API and not in the call stack.- Some functions in Node.js are written in C++ or other languages, not in JavaScript. These functions are called addons, and they are stored in a special place called Node APIs. Node APIs let Node.js use these functions from JavaScript code. One example of an addon is the
setTimeout()function, which uses a C library called libuv to create timers.- Node API refers to the functions and protocols that allow developers to interact with Node.js. C++ can be used to write native addons for Node.js, which can be accessed through the Node API.
- Now it reaches
setTimeout(() => { console.log('Delay 0 seconds..'); }, 0);

- Now inside Node APIs it will check which delay is less and it will be added to the callback queue.
By the way Node APIs make timer events and send them to libuv. Libuv handles them inside. Libuv tells Node.js when timer events are ready. Node.js puts them in the timer queue. The timer queue is a place to store different events. The event loop checks the timer queue and moves the events to the call stack when it is empty. The event loop does not care which delay is less. It cares which event is ready first, based on when they were added to the timer queue and how much time passed since then.

- By the time we reach to
console.log('Finished index.js'),setTimeout(() => { console.log('Delay 0 seconds..'); }, 0);was added to the call stack .

- Now you might be wondering why
setTimeout(() => { console.log('Delay 0 seconds..'); }, 0);is added to the call stack before and then go to the callback queue and then again added to the call stack.- The reason is that the event loop is constantly checking the call stack and the callback queue. If the call stack is empty, it will take the first task from the callback queue and push it to the call stack, which effectively runs it. This process will continue until the call stack is not empty or the callback queue is not empty.
- Now
setTimeout(() => { console.log('Delay 0 seconds..'); }, 0);will be executed and then it will be popped out of the call stack.

- Now
setTimeout(() => { console.log('Delay 2 seconds..'); }, 2000);will be added to the call stack.

- Now
setTimeout(() => { console.log('Delay 2 seconds..'); }, 2000);will be executed and then it will be popped out of the call stack.

⭐ More Detailed Explanation
Sometimes we have to scrape data from a slow website or wait for a long time to get the result of a database query. But we don't want to waste our time and stop other tasks from running because of that. Thanks to Libuv, a C++ library that handles the event loop and async tasks, Node.js can keep running other operations while working on tasks like database queries. Libuv also takes care of things like network requests, DNS resolution, file system operations, data encryption, etc.
How does Node.js handle tasks like database queries behind the scenes? Let's find out by looking at this code snippet step by step.
 (opens in a new tab)
Imagine you’re baking a cake. You have a recipe that tells you what to do step by step. The recipe is like the call stack - it keeps track of where you are in the process. When you start, the first step is added to the call stack. Once you complete that step, it’s removed from the call stack and the next step is added.
(opens in a new tab)
Imagine you’re baking a cake. You have a recipe that tells you what to do step by step. The recipe is like the call stack - it keeps track of where you are in the process. When you start, the first step is added to the call stack. Once you complete that step, it’s removed from the call stack and the next step is added.
- The V8 JavaScript engine manages a call stack which tracks which part of our program is running. Whenever we invoke a JavaScript function, it gets pushed to the call stack. Once the function reaches its end or a
returnstatement, it is popped off the stack.
For example,
- let's say we have a line of code that reads
console.log('Starting Node.js'). This line of code gets added to the call stack and printsStarting Node.jsto the console. Once it reaches the end of thelogfunction, it is removed from the call stack.
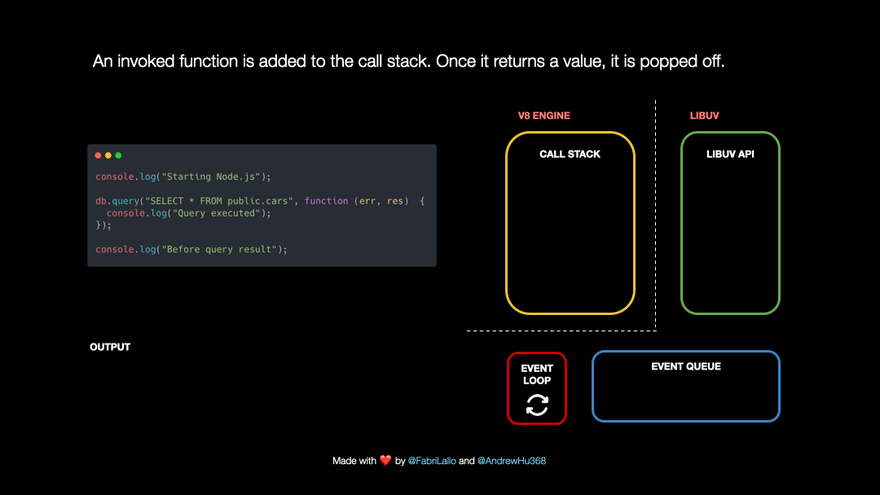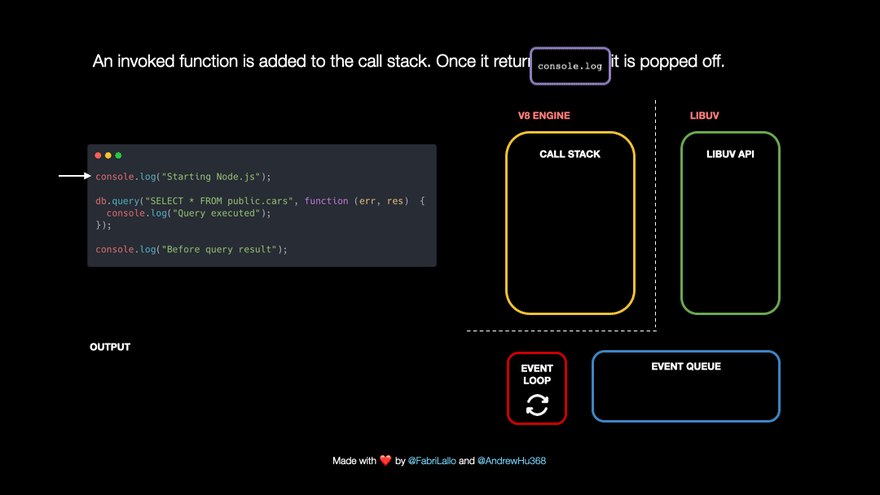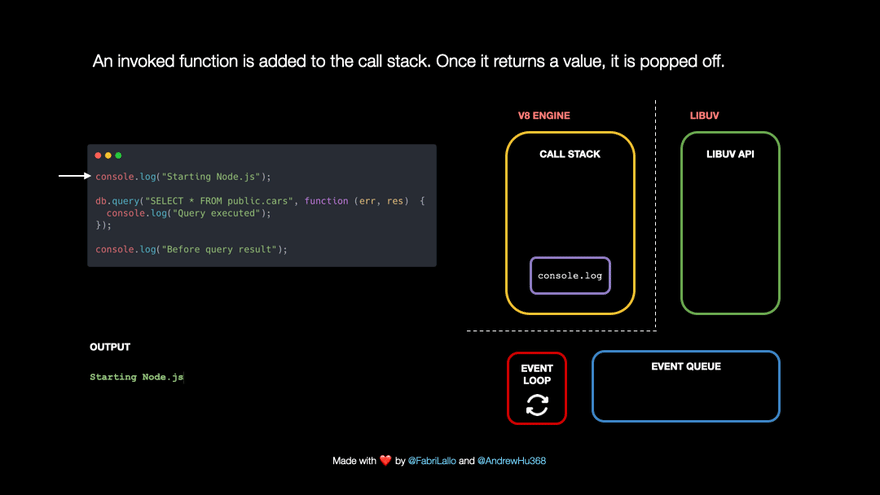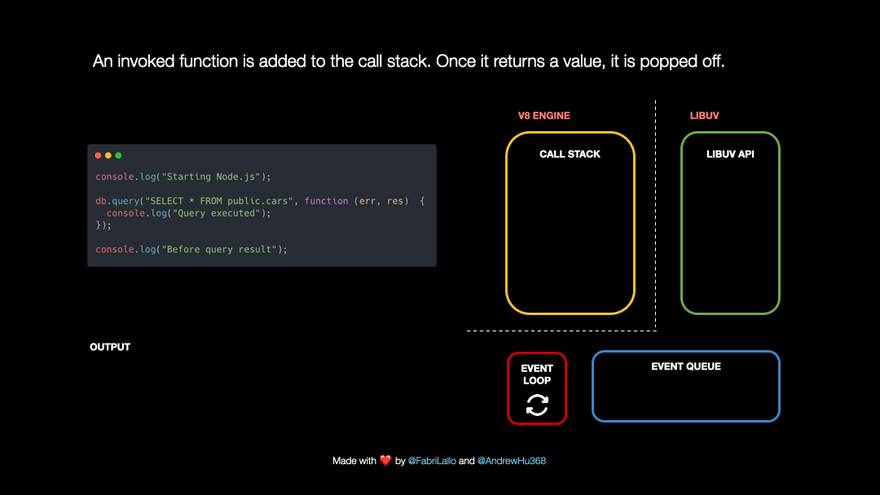
- The following line of code is a database query. These tasks are immediately popped off because they may take a long time. They are passed to Libuv which handles them asynchronously in the background. At the same time, Node.js can keep running other code without blocking its single thread.
- In the future, Node.js will know what to do with the query because we have associated a callback function with instructions to handle the task result or error.
- In our case, it is a simple
console.log, but it could be complex business logic or data processing in production applications.

- While Libuv handles the query in the background, our JavaScript is not blocked and can continue with
console.log(”Before query result”).
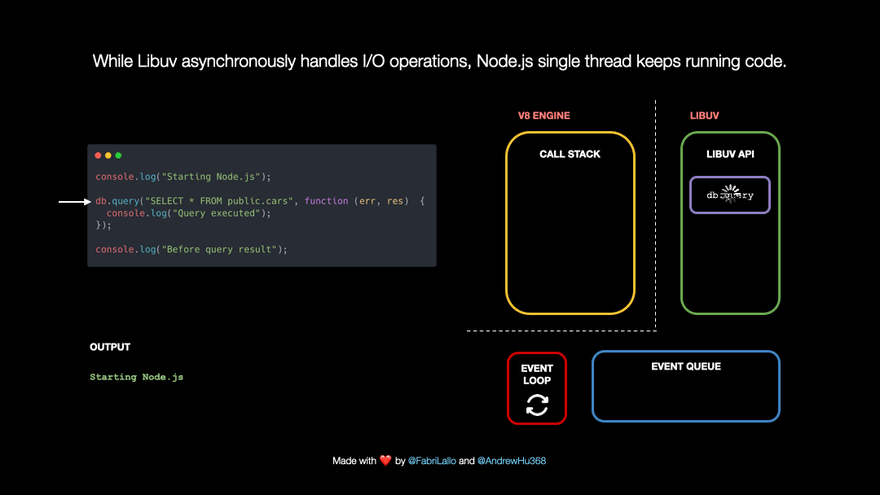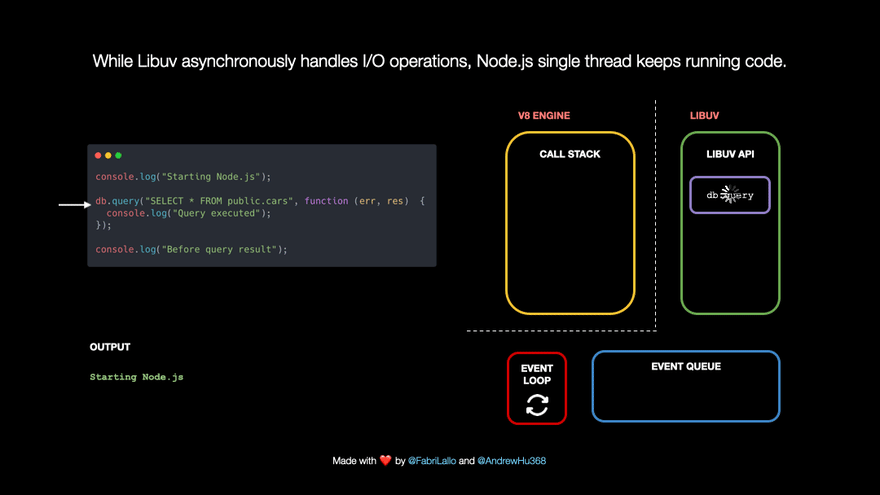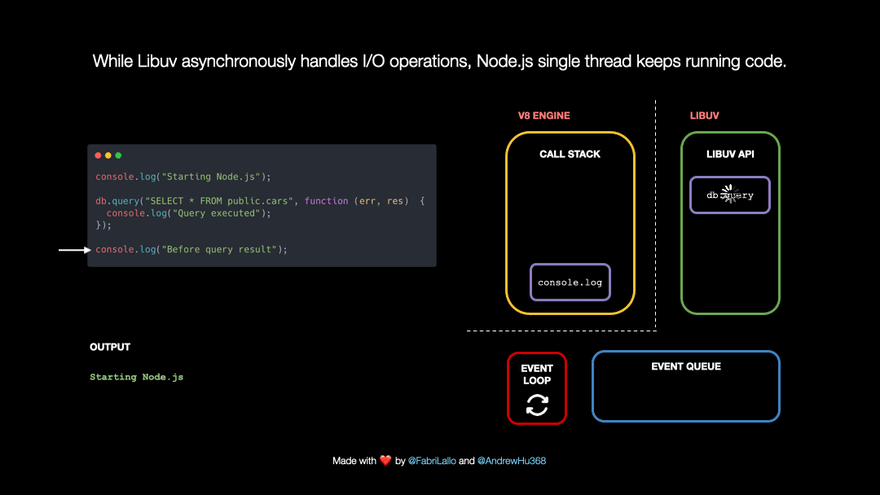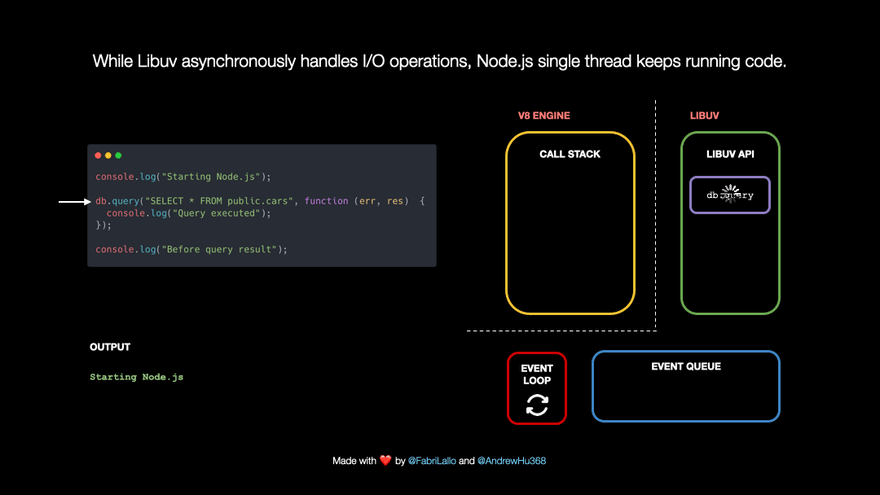
- When the query is done, its callback is pushed to the I/O Event Queue to be run shortly. The event loop connects the queue with the call stack. It checks if the latter is empty and moves the first queue item for execution.
